
Every time we said that applications of blockchain technology are not restricted to its use in cryptocurrency, we have on furthered the discussion on how else we might use it. We have, occasionally, spoken of business areas that might be disrupted by the technology, but we have not bothered to study the concept in their components. We have not shown in parts how the building blocks of a legacy system may be replaced by blockchain technology.
However, here is an instance of an effort made to construct a blockchain database. In what the researchers have proposed we find a “decentralized replicated relational database with blockchain properties” that they have called a blockchain relational database.
In the paper, the researchers have thrown light on a long list of similarities between features of blockchain platforms and a replicated relational database. And this, despite each being conceptually dissimilar – primarily in their trust model.
For this model, the researchers have considered a permissioned blockchain model of cognizant yet mutually distrustful organizations. Each organization works on its own database instance which are replicas of one another. The replicated databases execute transactions independently and are governed by decentralized consensus to determine the commit order for transactions.
Here the researchers have come up with two approaches to handle the tasks: in the first, the commit order for the transactions is agreed upon before their executions. In the second approach, the transactions are executed without prior signaling of the commit order with the ordering processes in parallel.
Researchers have leveraged serializable snapshot isolation (SSI) to ensure consistency among the replicas across nodes and also conform to the ordering determined by consensus. They have also devised a new variant of SSI based on block height for the latter approach. Next, they implemented the system on PostgreSQL and presented detailed performance experiments analyzing both approaches.
Also Read: Blockchain: The Technology, The Applications, and The Possibilities
In this paper, the researchers have addressed this key challenge of ensuring that all the untrusted database nodes must execute transactions independently and commit them in the same serializable order asynchronously. To achieving this, two key design choices were made.
First, they modified the database to separate the concerns of concurrent transaction execution and decentralized ordering of blocks of transactions. They leveraged ordering through consensus only to order blocks of transactions, and not for the serializable ordering of transactions within a single block. Second, independently at each node, the researchers leveraged serializable snapshot isolation (SSI) to execute transactions concurrently and then serially validate and commit each transaction in a block. This is done to obtain a serializable order that will be the identical across all untrusted nodes and will respect the ordering of blocks obtained from consensus. Applying these ideas, the researchers have come up with two novel approaches, the first is the scenario where block ordering is performed before transaction execution. The second scenario arises where transaction execution occurs parallelly without prior knowledge of block ordering, and discuss their trade-offs. We leverage and modify serializable snapshot isolation to create a novel variant which promises the same serializable ordering across all nodes. They implement their ideas on PostgreSQL going over the subtle challenges they had to overcome.
Also Read: Blockchain Shootout: Unlearn These 5 Common Myths on Blockchain Technology
A permissioned network of organizations aware of each other’s existence but mutually distrustful is the ground we focus on. The network is typically private to the participating organizations. A new organization has to be permissioned to become apart of the
network. Each participating organization includes clients, database peer nodes and ordering service nodes. This structure is described below, that as a cluster form the decentralized network.
Client: Each organization has a designated administrator charged with onboarding client users onto the network. This administrator and each client possess a digital certificate registered with all the database peers in the system. They use these certificates to digitally sign and submit transactions on the network. This helps bolster authenticity, non-repudiability and access control properties. Clients also come with the ability to listen on a notification channel to receive transaction status.
Database Peer Node: An organization may operate one or more database nodes in the network. All communication to send and receive transactions and blocks happens via a secure communication protocol such as TLS. Each node has a cryptographic identity (i.e., public key) assigned. This enables all communications to be signed and authenticated cryptographically. Each database node is responsible for maintaining its own replica of the ledger as database files. It is able to independently execute smart contracts as stored procedures, and validates and commits blocks of transactions formed by the ordering service.
Ordering Service: Consensus is needed to guarantee that the untrusted database nodes agree on an ordering of blocks of transactions. The ordering service comprises of consensus or orderer nodes, each owned by a distinct organization. Every orderer node, similar to database nodes, have their own digital certificate or identity. The consensus results in a block of transactions, which is then atomically broadcast to all the database nodes. A block consists of (a) a sequence number, (b) a set of transactions, (c) metadata associated with the consensus protocol, (d) hash of the previous block, (e) hash of the current block, i.e., hash (a, b, c, d); and (f) digital signature on the hash of the current block by the orderer node.
A transaction made by a client in the order-then-execute approach comprises of
(a) a unique identifier,
(b) the username of the client,
(c) the PL/SQL procedure execution command with the name of the procedure and arguments, and
(d) a digital signature on the hash(a, b, c)
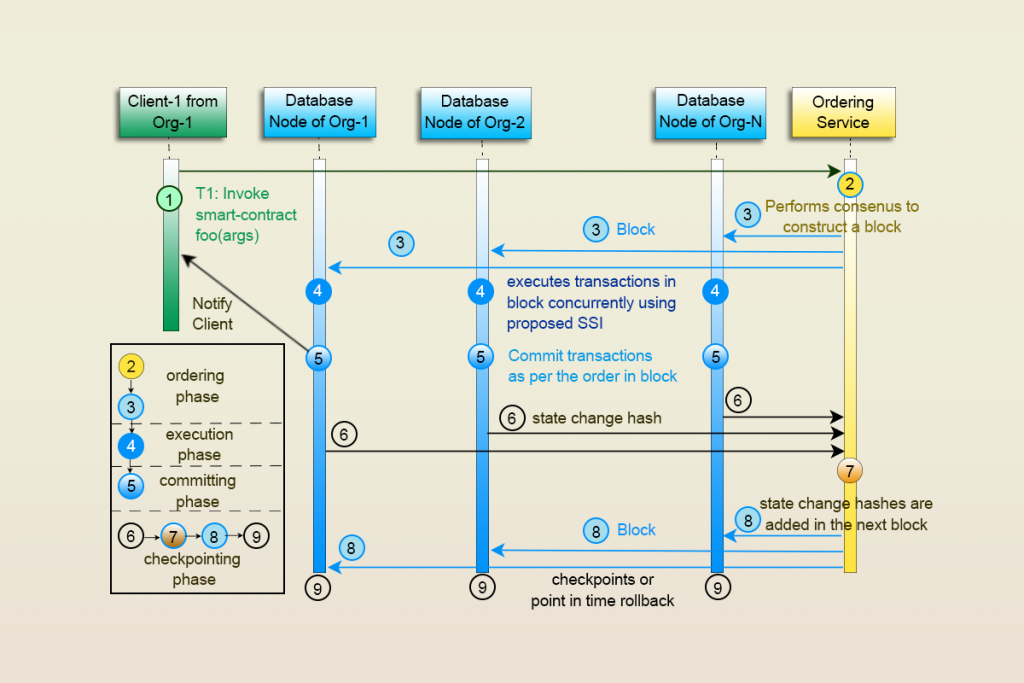
using the client’s private key. Four pipelined phases comprise the transaction flow: ordering, execution, committing, and checkpointing. Here a submitted transaction needs to first be ordered, next executed, and finally committed before being written on a checkpoint.
When a Client submits transactions directly to any one of the ordering service nodes, a periodic timeout (say every 1 second) is started. The ordering service nodes initiate a consensus protocol among themselves to construct a block of transactions. After constructing a block, the ordering service delivers it to all nodes in the network via atomic broadcast.
The Database nodes receive a block of transactions. Each database node verifies whether the received block is in sequence and forwarded by the ordering service. Upon successful verification, the node appends the block to a block store which is maintained in the local file system. Parallely, the node retrieves unprocessed blocks one at a time, in the order of their block sequence number, from the block store and processes them four sequential steps.
Ensuring that the commit order is the same on all nodes, the order in which the transactions get committed is exactly how the transactions appear in the block. Once all valid transactions are executed and are ready to be either committed or aborted, the node serially notifies one thread at a time to proceed further. Each transaction applies the abort during commit approach to determine whether to commit. Accomplishing this does the next transaction enter the commit stage.
When all transactions in a block are executed, each node computes the hash of the write set. The is the result of the union of all changes made to the database by the block. Thereafter, the node submits it to the ordering service as a proof of execution and commit. When a node receives the subsequent blocks, it also would receive the hash of write set computed by other nodes. The hash computed by all non-faulty nodes would result in the exact same value and the node then proceeds to record a checkpoint. It is,however, not necessary to record a checkpoint corresponding to every block. Rather, the hash of write sets can be computed for a preconfigured number of blocks and then forwarded to the ordering service.
A transaction submitted by a client in the execute-orderin-parallel approach comprises of
(a) the username of the client,
(b) the PL/SQL procedure execution command with the name of the procedure and arguments,
(c) a block number,
(d) a unique identifier which is computed as hash(a, b, c), and
(e) a digital signature on the hash(a, b, c, d)
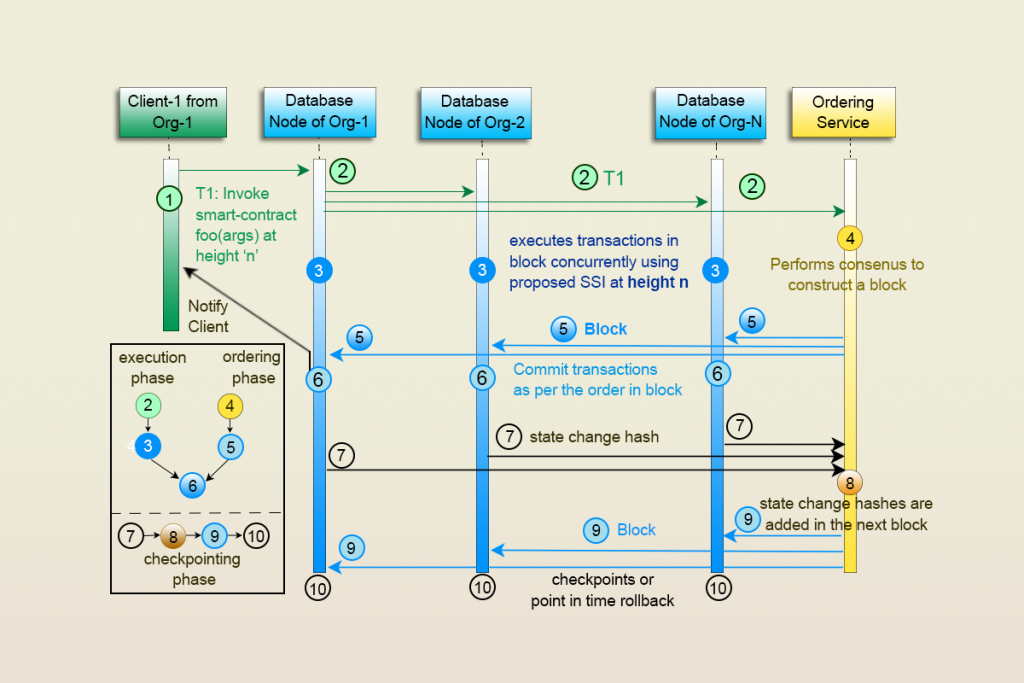
using the client’s private key. The transaction flow is comprised of four phases: execution, ordering, committing, and checkpointing phase. A submitted transaction is processed by the
database nodes and in parallel according to the ordering nodes and is written on a block. This is followed by the commit and checkpoint phases. We describe each phase in detail below:
Clients submit transactions directly to one of the database nodes. Upon receiving a transaction, a node assigns a thread to authenticate, forward and execute the transaction.
On successful authentication (same as in the order-thenexecute approach), the transaction is forwarded to other database nodes and the ordering service in the background.
Here database nodes submit transactions to the ordering service unlike the order-then-execute approach. It must be noted that the transactions are being executed in the database nodes while they are being ordered by the ordering service, concurrently.
As in the case of order-then-execute approach, an important pre-condition for transactions entering commit phase is that all transactions in a block must have accomplished its execution and are waiting to proceed with commit/abort. However, they are different from the former approach in some ways.
First, after receiving a block, if all transactions are not running, the committer begins executing all the missing transactions and waits for their completion. The comitter then proceeds to the committing phase. Second, unlike the former approach, it is possible for concurrent transactions to be executed at different snapshot heights (as specified by the respective clients). Finally, transactions, concurrent on one node, may not be concurrent on another. However, the set of transaction is needed, that is decidedly to be committed, to be identical on all nodes. As a result, the system doesn’t support blind updates such as UPDATE table SET column = value; which might result in a lock for ww-dependency only on a subset of nodes.
Checkpointing Phase is the same as in the former approach.
In this paper, researchers have presented the design of a blockchain relational database, which is a decentralized database with replicas managed by different organizations that do not trust one another. The key challenge addressed here is in ensuring that all untrusted replicas commit transactions in the same serializable order that respects the block ordering determined by consensus.





No Comment